
数学建模
数学建模
xingzhu评价类—决策
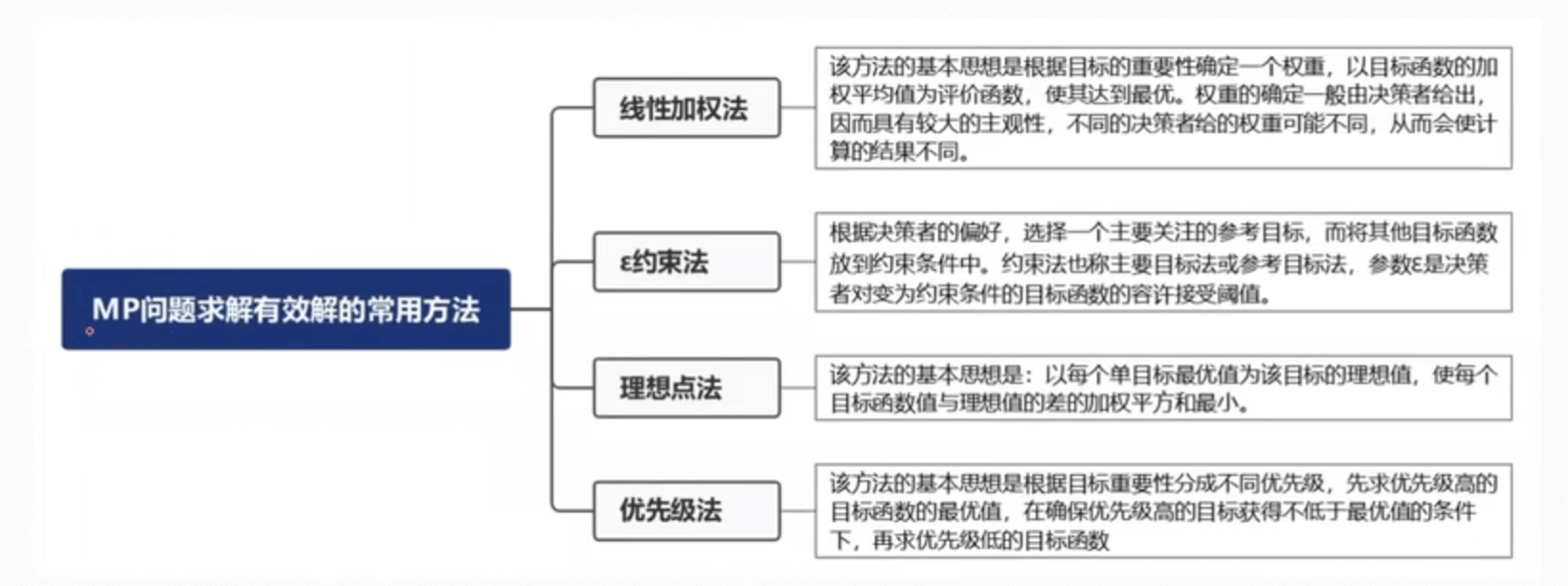
层次分析法—-定权(相对客观)
一致矩阵的条件
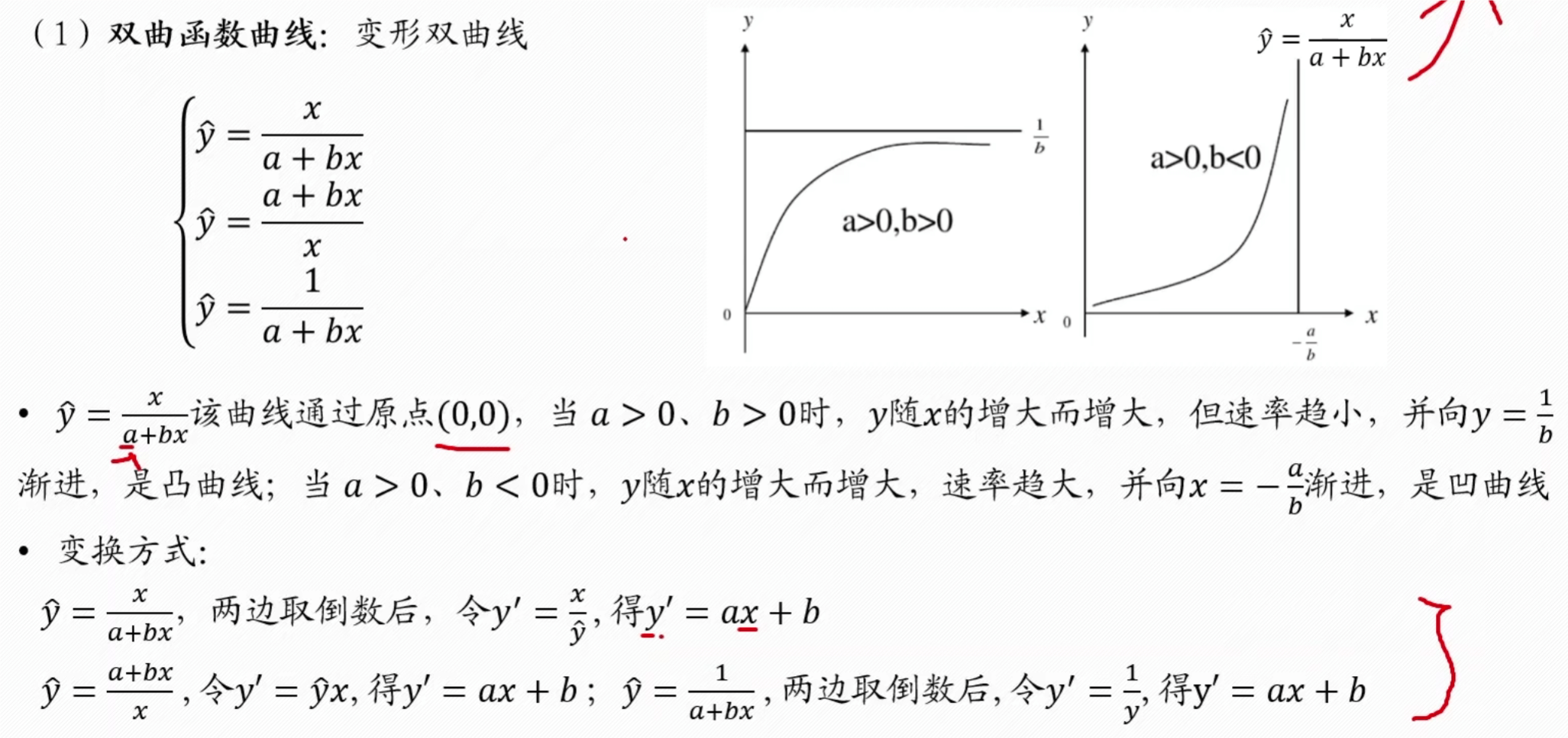
归一化是指将其加起来,看占的比重

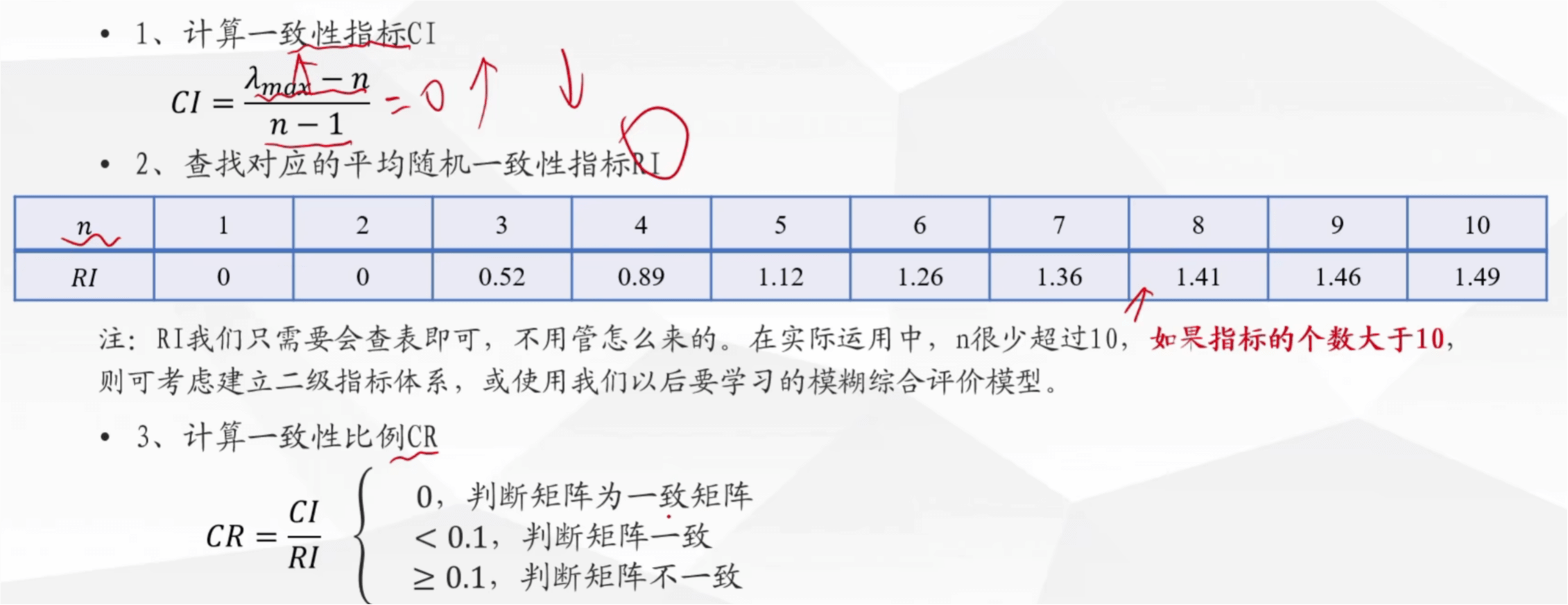
求权重的方法

1 | # 示例 |

1 | # 示例 |

1 | import numpy as np |
TOPSIS 法



1 | # 假设指标权重都同 |
熵权法
原理:计算熵值,熵值越小,离散程度越大,对其影响大,权重越大


1 | import numpy as np # 导入numpy库,并简称为np |
模糊法
基本步骤
- 首先确定因素集(指标):志愿服务,智育成绩,综合成绩
- 然后确定评语集:优,良好,中等,差
- 确定权重集:可以由专家评价,也可以计算权重的方法计算,得到集合 A
- 确定模糊综合判断矩阵

- 对于上述的模糊判断矩阵求法
- 找群众打分
- 由函数求得
- 进行矩阵合成运算:B = A . R
- 然后找矩阵 B 中的最大值,就选它


隶属函数:将指标的值映射到【0,1】,隶属度越大,属于这个集合的程度越大


灰色关联分析法
灰色关联评价的基本步骤:
对数据进行正向化处理
对数据预处理:每个指标的元素除以该指标元素的平均值,得到一个新矩阵,这个矩阵使用 Zij 表示
构造母序列:每个对象各个指标中的最大值,用 Y 表示,是一个列向量
找到两极最小值和两极最大值
- 最小值为例:当前指标的一列中,各个对象的指标值减去母序列的值,去绝对值最小的一个数,这是一部分,然后各个指标都如此操作,找到最小值,取这些最小值中的最小值即为两极最小值
- 两极最小值记为 a,两极最大值记为 b
在带入公式
计算这个值,得到矩阵(这里面的 x0 是母序列,xi(k)是子序列计算得分并归一化
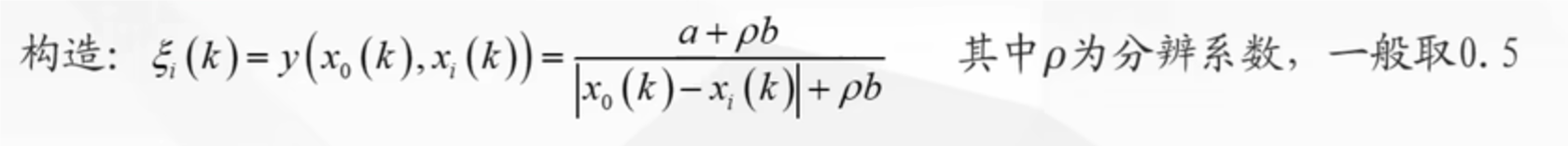 计算这个值,得到矩阵(这里面的 x0 是母序列,xi(k)是子序列
计算这个值,得到矩阵(这里面的 x0 是母序列,xi(k)是子序列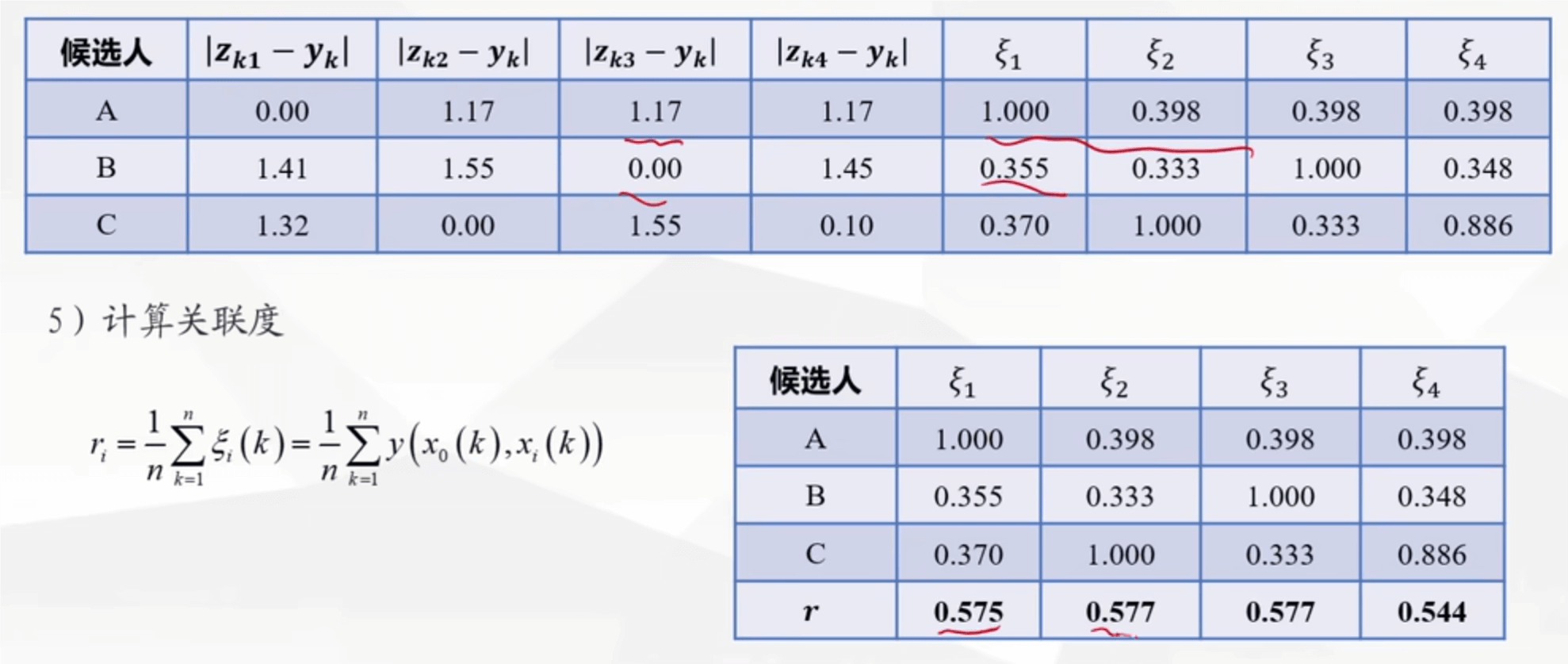

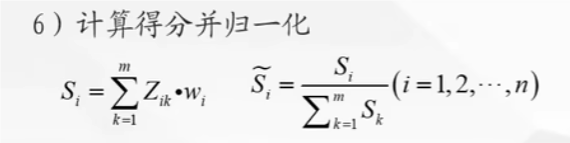
1 | # 灰色关联分析代码 |
主成分分析
这个模型主要是用来降维的,就是把多的变量替换成几个精简的变量,这些变量都能概括出原有变量的意义
使用主成分分析,找出的主成分,要考虑自己能否解释清楚这些主成分,因为看到数据不一定好解释
基本步骤:
对原始的样本矩阵进行标准化处理
计算特征值和特征向量,注意计算出的特征向量排序后,在带入特征值求出特征向量,这是一 一对应的,即 a1 是最大特征值所得出的特征向量
- 这个是指当前主成分所携带携带原有数据的信息量多少
按照主成分的组成,各个指标所占的比重,即 a1i , a2i,推断出此时的成分的新的意义,解释出含义,这往往是最难的





1 | import pandas as pd |
运筹优化类
线性规划
基本步骤:
将题目转换为代数形式
找出目标函数,决策变量,上述目标函数就是 maxz,决策变量用
s.t表示,注意一些隐含的约束条件,比如x>=0注意约束条件的每一个表达式,如果 x 对应的系数为 0,也要写出 0
如果题目转换后有两个目标函数,就将其想办法能不能转换为单一目标函数进行,一般是找关系,比如其中一个目标是让风险尽可能小,那么假设最大的一个风险是多少,将这个目标函数转换为约束条件,然后可以枚举风险到当前假设的最大风险,看情况如何,风险对应的收益

==注意:这个适用于小数的计算,整数规划问题不适用==


解释:
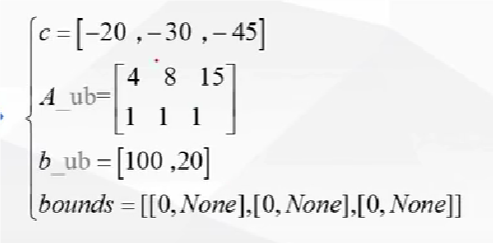
- 上述的代数形式都需要转换为矩阵形式,c 就是变量 x 前面的序数组成的矩阵
- 这个约束条件必须是小于等于,不是的话需要转换,如加负号,然后这个函数是求最小值,求最大值,加负号转换目标函数
例子: 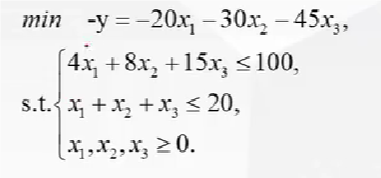
示例:一个有多目标函数的实现代码
1 | # 导入必要的库 |
结果: 
非线性规划
和线性规划类似的思路,函数不同
1 | import scipy |
参数解释:
fun:目标函数:fun (x, * args)x 是形状为 (n, ) 的一维数组 (n 是自变量的数量)x0:初值,形状 (n,) 的 ndarraymethod:求解器的类型。如果未给出,有约束时则选择SLSQP。constraints:求解器 SLSQP 的约束被定义为字典的列表,字典用到的字段主要有:'type': str:约束类型:"eq"表示等式,"ineq"表示不等式 (SLSQP 的不等式约束是 f( x ) ≥ 0 形式'fun':可调用的函数或匿名函数:定义约束的函数
bounds: 变量界限
例子: 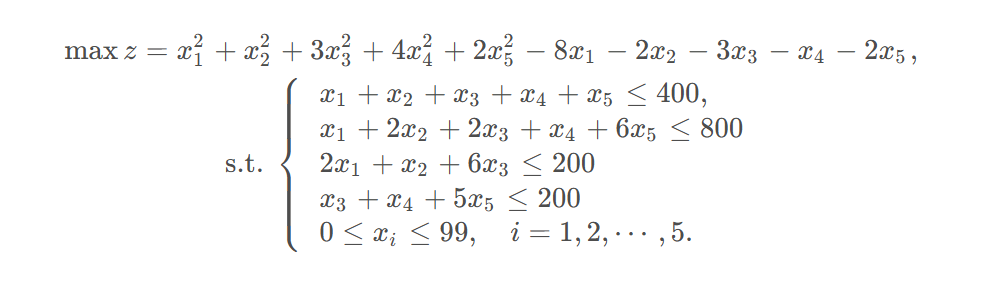
1 | from scipy.optimize import minimize |
多目标规划
==其中,那个约束法就是线性规划中化解为单目标函数的方法==

注意:
- fi 权重一般是由专家或者其他方式所得
- 要将多个目标函数统一为最大化和最小化问题 (不同的加 “ - ” 号)才可以进行加权组合
- 如果目标函数量纲不同,则需要对其进行标准化再进行加权,标准化的方法一般是目标函数除以某一个常量,该常量是这个目标函数的某个取值,具体取何值可根据经验确定
- 这个常量有可能题目中会告诉一个参考值
- 对多目标函数进行加权求和是,权重一般由该领域专家给定,实际比赛中,若无特殊说明,我们可令权重相同
例子: 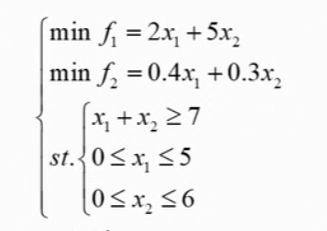
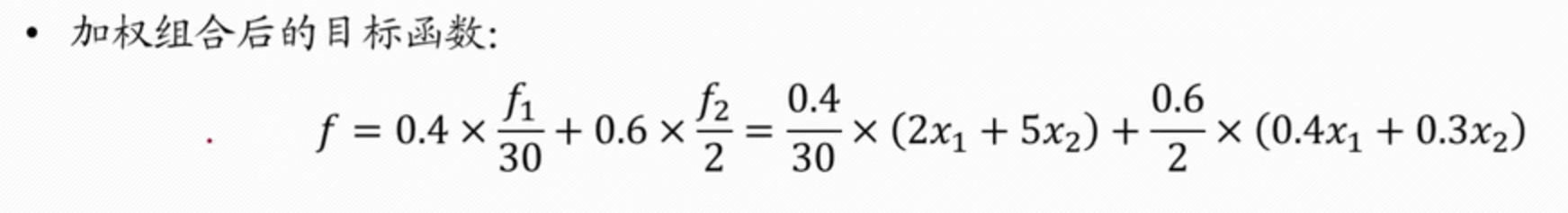
- 上述假设的 f1 的权重为 0.4,f2 的权重为 0.6,参考值 f1 的值为 30 万元,f2 为 2 吨
- 所以这就是合并后的量纲不同
- 转换好了,就用上述线性规划的函数求解
一般数模问题可以进行敏感度分析:就是变化变量值,看结果的差异性比较,进行分析问题 比如这里的权重,变化之后,看结果有何不同,进行分析
启发式算法
模拟退火
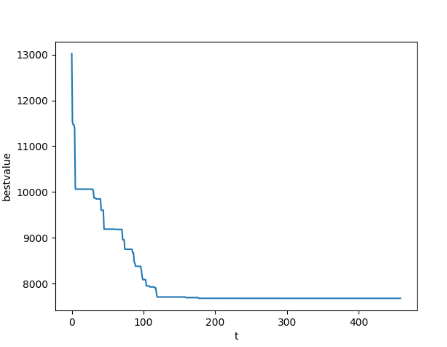
示例:解决旅行商问题(TSP 问题)
- 初始化解:随机生成一个初始路径,表示旅行商依次访问城市的顺序。
- 设定初始温度:初始时,系统的 “温度” 很高,容许接受较差的解。初始温度的选择对算法的性能有影响,通常由问题的特性和经验决定。
- 迭代过程:在当前解的基础上进行微小的扰动,例如交换两个城市的顺序,得到一个新的解。计算新解的路径长度与当前解的路径长度之差(ΔE)。如果 ΔE 小于 0,即新解更优,直接接受新解。如果 ΔE 大于 0,以一定的概率(由温度和 ΔE 决定)接受新解。温度高时,概率较大,有较大可能性接受劣解;随着迭代进行,温度逐渐降低,接受劣解的概率减小,算法越来越趋向于选择更好的解。
- 降低温度:在每个迭代步骤后,通过一个降温策略减小温度。典型的降温策略是乘以一个小于 1 的因子。
- 终止条件:当温度降低到足够低(接近零)或者达到最大迭代次数时停止算法。此时,当前解即为所求解。
copy博主代码:模拟退火算法解决TSP问题+Python实现_天池技术圈-阿里云天池 (aliyun.com)
1 | import numpy as np |
预测类
线性回归
直线方程参数求解
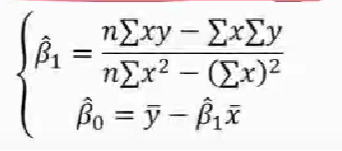
y = β0 + β1x1 + e e 是误差,属于正态分布,E(e) = 0
检验
回归直线拟合优度
- 回归直线与各观测点的接近程度称为回归直线对数据的拟合优度

- 总平方和可以分解为回归平方和、残差平方和两部分:TSS = ESS + RSS
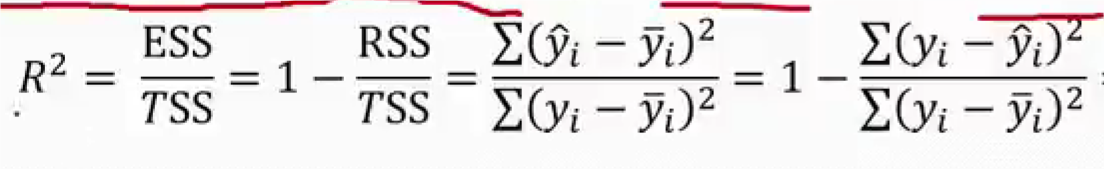
- R2 = 0:说明 y 的变化与 x 无关,x 完全无助于解释 y 的变差
- R2 = 1:说明残差平方和为 0,拟合是完全的,y 的变化只与 x 有关
==显著性检验==
- 显著性检验的主要目的是根据所建立的估计方程用自变量 x 来估计或预测因变量 v 的取值,当建立了估计方程后,还不能马上进行估计或预测,因为该估计方程是根锯样本数据得到的,它是否真实的反映了变量 x 和 y 之间的关系,则需要通过检验后才能证实
线性关系检验
- 线性关系检验是检验自变量 X 和因变量 Y 之间的线性关系是否显著,或者说,它们之间能否用一个线性模型来表示
- 将均方回归(MSR)与均方残差(MSE)加以比较,应用 F 检验来分析二者之间的差别是否显著
- 均方回归(MSR):回归平方和 EES 除以相应的回归自由度(自变量的个数 k)
- 均方残差(MSE):残差平方和 RRS 除以相应的残差自由度(n-k-1)
- H0 (原假设):β1=0,回归系数与 0 无显著差异,y 与 x 的线性关系不显著
- H1:β1≠0,回归显著,认为 y 与 x 存在线性关系,所求的线性回归方程有意义
- 计算检验统计量 F:
- H0 成立时,$$ F = \frac{\frac{ESS}{1}}{\frac{RSS}{n-2}} = \frac{MSR}{MSE} \sim F(1, n-2) $$
- 若 F > F1-a (1, n-2),拒绝 H0,否则接受 H0
回归系数检验
- 回归系数显著性检验的目的是通过检验回归系数 β 的值与 0 是否有显著性差异,来判断 Y 与 X 之间是否有显著的线性关系,若 β=0,则总体回归方程中不含 X 项 (即 Y 不随 X 变动而变动),因此,变量 Y 与 X 之间并不存在线性关系;若 β ≠ 0,说明变量与 X 之间存在显著性的线性关系

线性关系检验与回归系数检验的区别
- 线性关系的检验是检验自变量与因变量是否可以用线性来表达,而回归系数的检验是对样本数据计算的回归系数检验是否为 0
- 在一元线性回归中,自变量只有一个,线性关系检验与回归系数检验是等价的
- 在多元回归分析中,这两种检验的意义是不同的。线性关系检验只能用来检验总体回归关系的显著性,而回归系数检验可以对各个回归系数分别进行检验
估计和预测
- 点估计:利用估计的回归方程,对于 x 的某一个特定的值,求出 y 的一个估计值就是点估计
- 区间估计:利用估计的回归方程,对于 x 的一个特定值,求出 y 的一个估计值的区间就是区间估计
估计标准误差
- 为了度量回归方程的可靠性,通常计算估计标准误差度量观察值回绕着回归直线的变化程度或分散程度
- 估计标准误差越大,则数据点围绕回归直线的分散程度就越大,回归方程代表性就越小
- 估计标准误差越小,则数据点围绕回归直线的分散程度越小,回归方程的代表性越大,可靠性越高

- y 是给的样本,y^ 是估计的方程上的点,就是 x 同下的 y^,这也是残差平方和,分子
- 分母是样本数量 - 变量数量
置信/预测区间估计
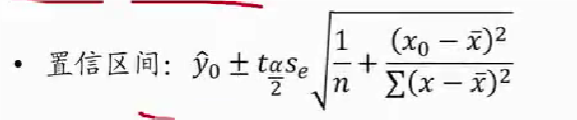
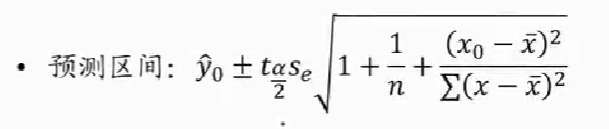
非线性回归
- 首先根据数据画出图像,也就是散点图,然后根据散点图大致推测是什么类型曲线,指数型,x2…..
- 根据这个曲线,转换为线性回归形式,利用线性回归求得系数
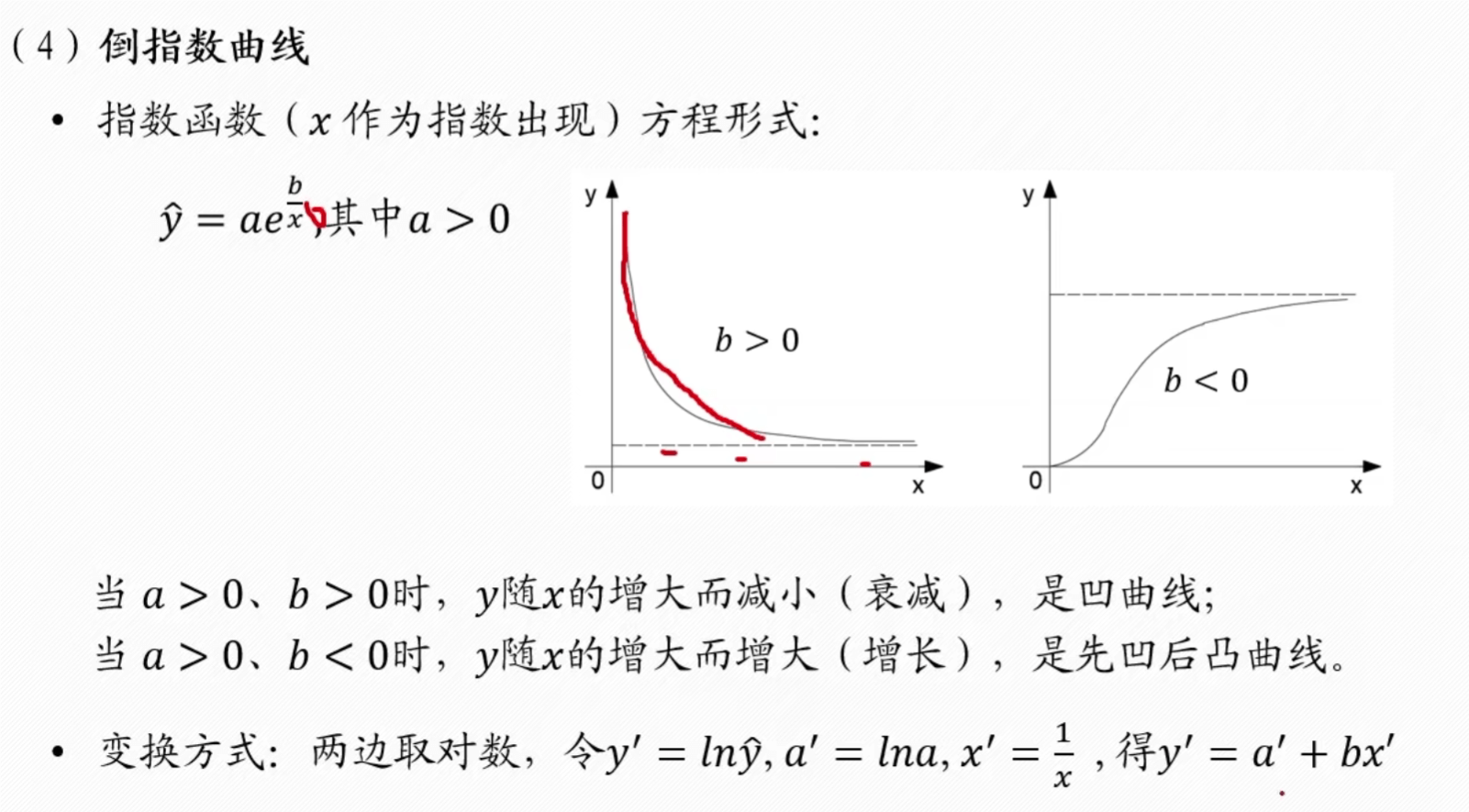
- 比如下面的倒指数形式的,转换为 y’ = a’ + bx’ 后,y’ 可以根据 y 算出,然后后面同理,就能根据一元线性回归的方程计算出系数 a’, b’,就能算出原方程形式
双曲线
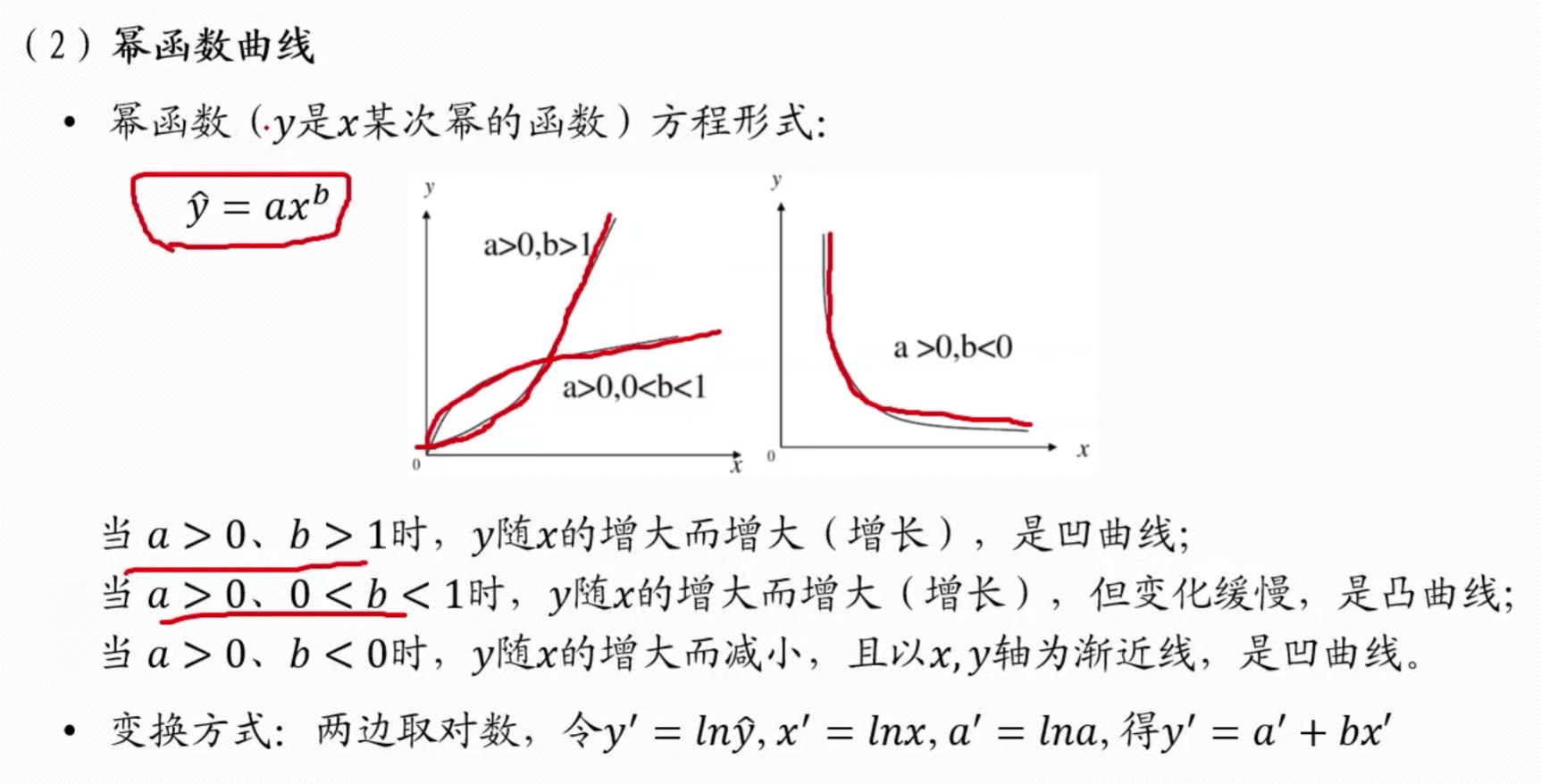
幂函数
指数

倒指数
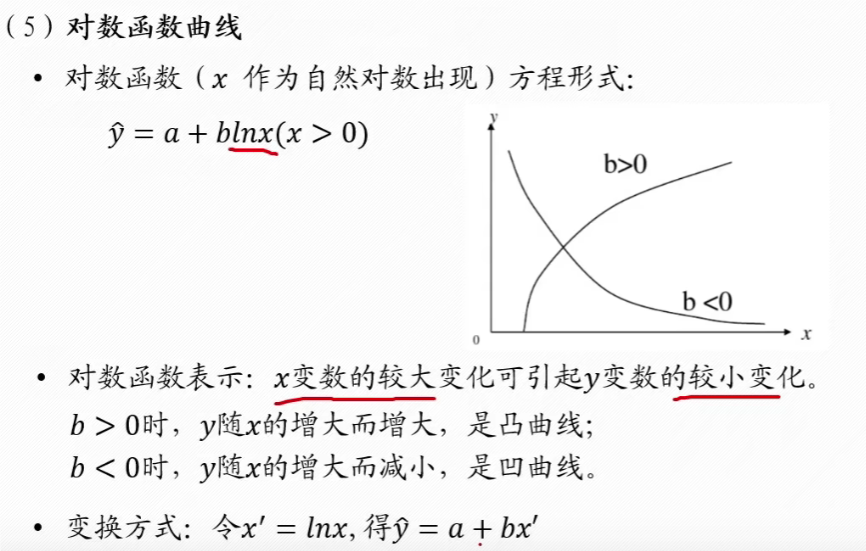
对数
S 型曲线
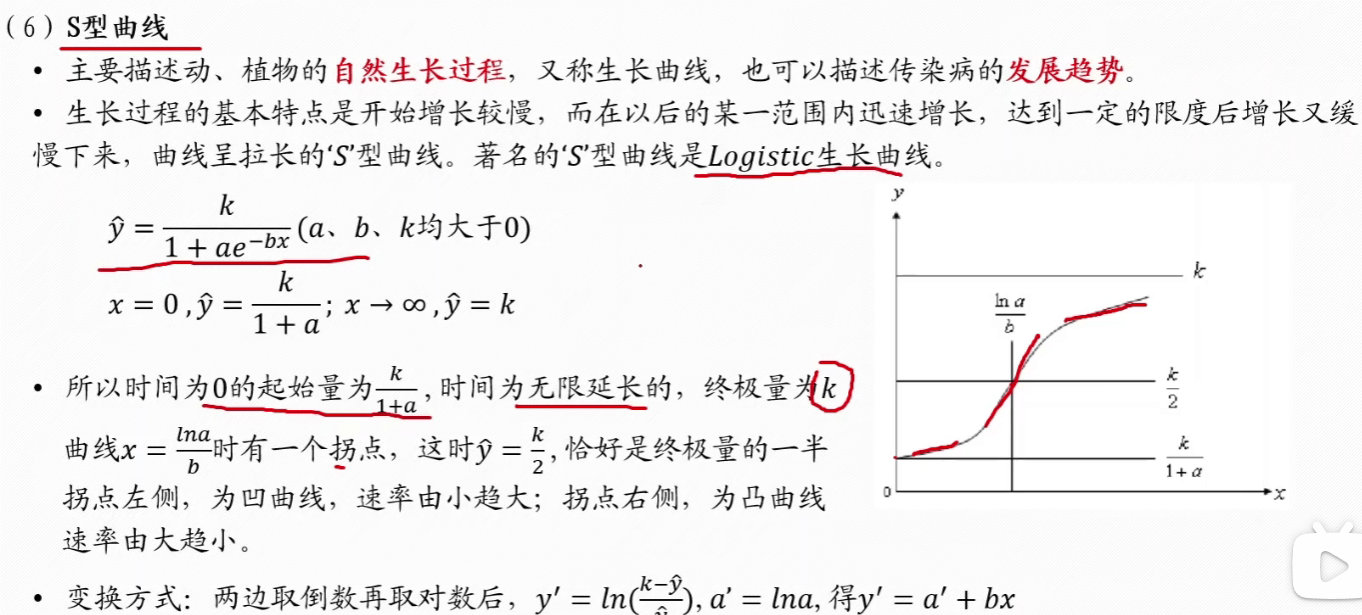
如果曲线都不是上述的,使用一般方法

灰色预测 GM (1, 1)
- 所谓灰色预测,就是对既含有已知信息又含有不确定信息的系统进行预测,就是对在一定围内变化的、与时间有关的灰色过程进行预测
适用:
- 数据是以年份度量的非负数据 (如果是月份或者季度数据一般要用时间序列模型),比如定时求量的题目,即已知一些年份数据,预测下一年的数据,常见有 GDP、人口数量、耕地面积、粮食产量等;或者定量求时,已知一些年份数据和某灾变的阈值,预测下次灾变时间
- 数据能经过准指数规律的检验 (除前两期外,后面至少 90%的期数的光滑比要低于0.5)
- 数据的期数较短且和其他数据之间的关联性不强 (小于等于 10,数据的期数较短且和其他数据之间的也不能太短了,比如只有 3 期数据),要是数据期数较长,一般用传统的时间序列模型比较合适
总体思路:
- 根据原始的离散非负数据列,通过累加等方式削弱随机性、获得有规律的离散数据列
- 建立相应的微分方程模型,得到离散点处的解
- 再通过累减求得的原始数据的估计值,从而对原始数据预测
步骤:
将数据描图,发现没有规律
若新曲线想指数曲线,那么利用指数曲线的表达式逼近 x(1)
构建一阶常微分方程,求解拟合指数曲线的函数表达式 $$ \frac{dx^{(1)}}{dt} + ax^{(1)} = u $$
为了求解 x(1),求解出 a 和 u
利用线性规划或者最小二乘法求解,因为 x(0) 和 z(1 )已知
检验
对原始数据检验,判断是否可以用灰色预测模型,进行级比检验
检验模型对原始数据的拟合程度

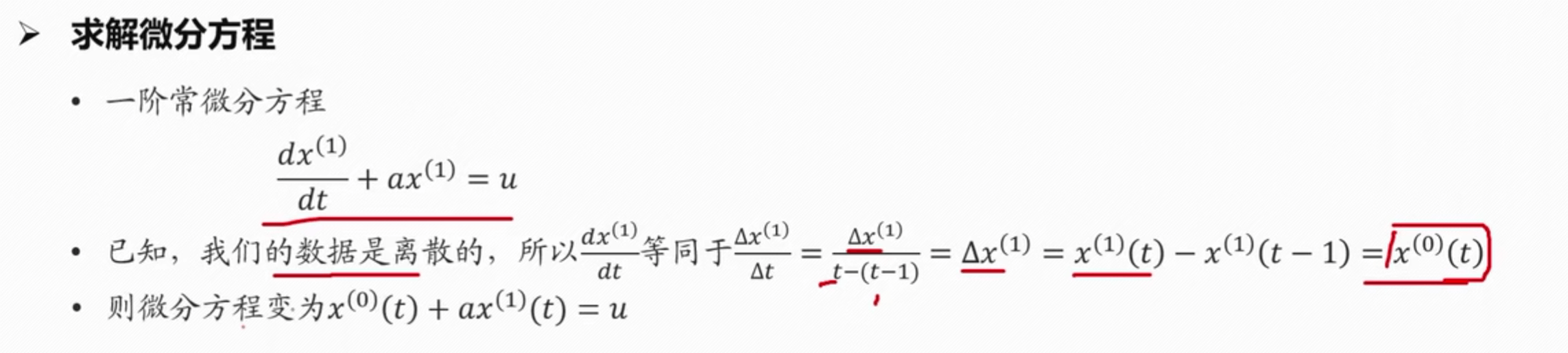



时间序列模型(ARIMA)
几种模型


白噪声是指误差的随机选择


ARIMA 模型的建模步骤:
- 对序列绘图,进行平稳性检验,观察序列是否平稳; 对于非平稳时间序列要先进行 d 阶差分,转化为平稳时间序列;
- 经过第一步处理,已经得到平稳时间序列。要对平稳时间序列分别求得其自相关系数 (ACF)和偏自相关系数 (PACF),通过对自相关图和偏自相关图的分析或通过 AIC/BIC 搜索,得到最佳的阶数 p、q;
- 由以上得到的 d、q、p,得到 ARIMA 模型。然后开始对得到的模型进行模型检验
平稳性
- 平稳性就是要求经由样本时间序列所得到的拟合曲线在未来的一段时间内仍然能够按照现有的形态延续下去
- 平稳性要求序列的均值和方差不发生明显变化
- 严平稳:序列所有的统计性质(期望,方差)都不会随着时间的推移而发生变化
- 宽平稳:期望与相关系数(依赖性)不变,就是说 t 时刻的值 X 依赖于过去的信息
- 实际数据大致上都是宽平稳
- 如果一个时间序列不是平稳的,通常需要通过差分的方式将其转化为平稳时间序列
画图看,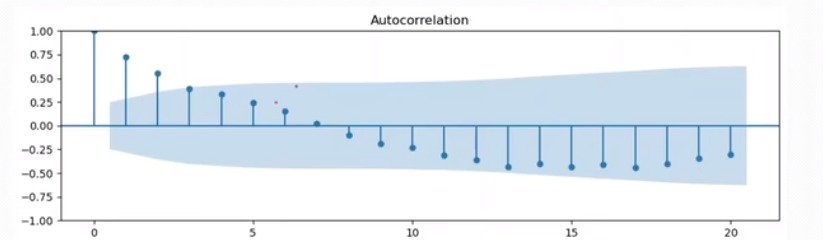 蓝色部分为置信区间,发现几乎都位于置信区间之中,说明训练集就是一个平稳序列,不需要差分了
蓝色部分为置信区间,发现几乎都位于置信区间之中,说明训练集就是一个平稳序列,不需要差分了
==差分法实现==
时间序列在 t 和 t-1 时刻的差值 $$\Delta yx = y(x + 1) - y(x),(x = 0,1,2,…) $$
一般差分次数不易过多,最高2、3 次即可
自相关系数 (ACF)与偏自相关系数(PACF)

ADF 检验
- 判断是否是平稳序列的一个计算方法
- ADF 检验就是判断序列是否存在单位根:如果序列平稳,就不存在单位根;否则,就会存在单位根
1 | import numpy as np |
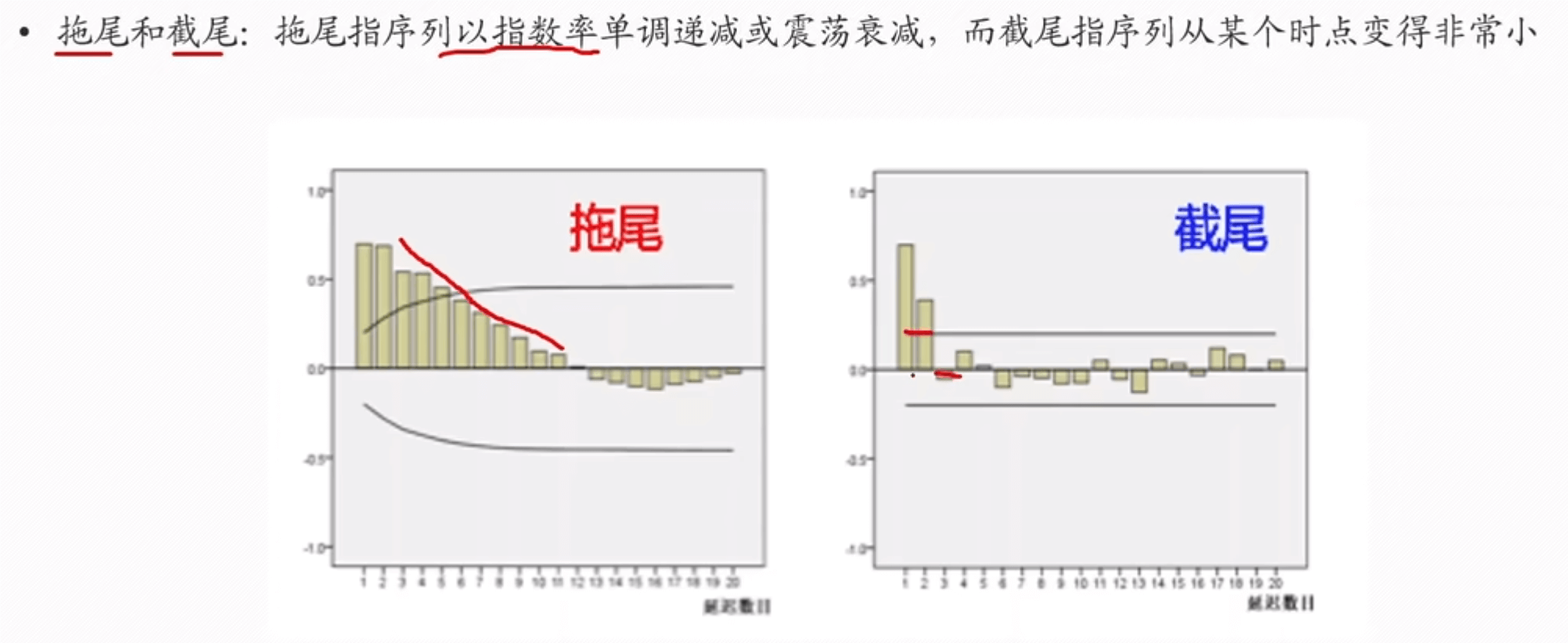
拖尾和截尾
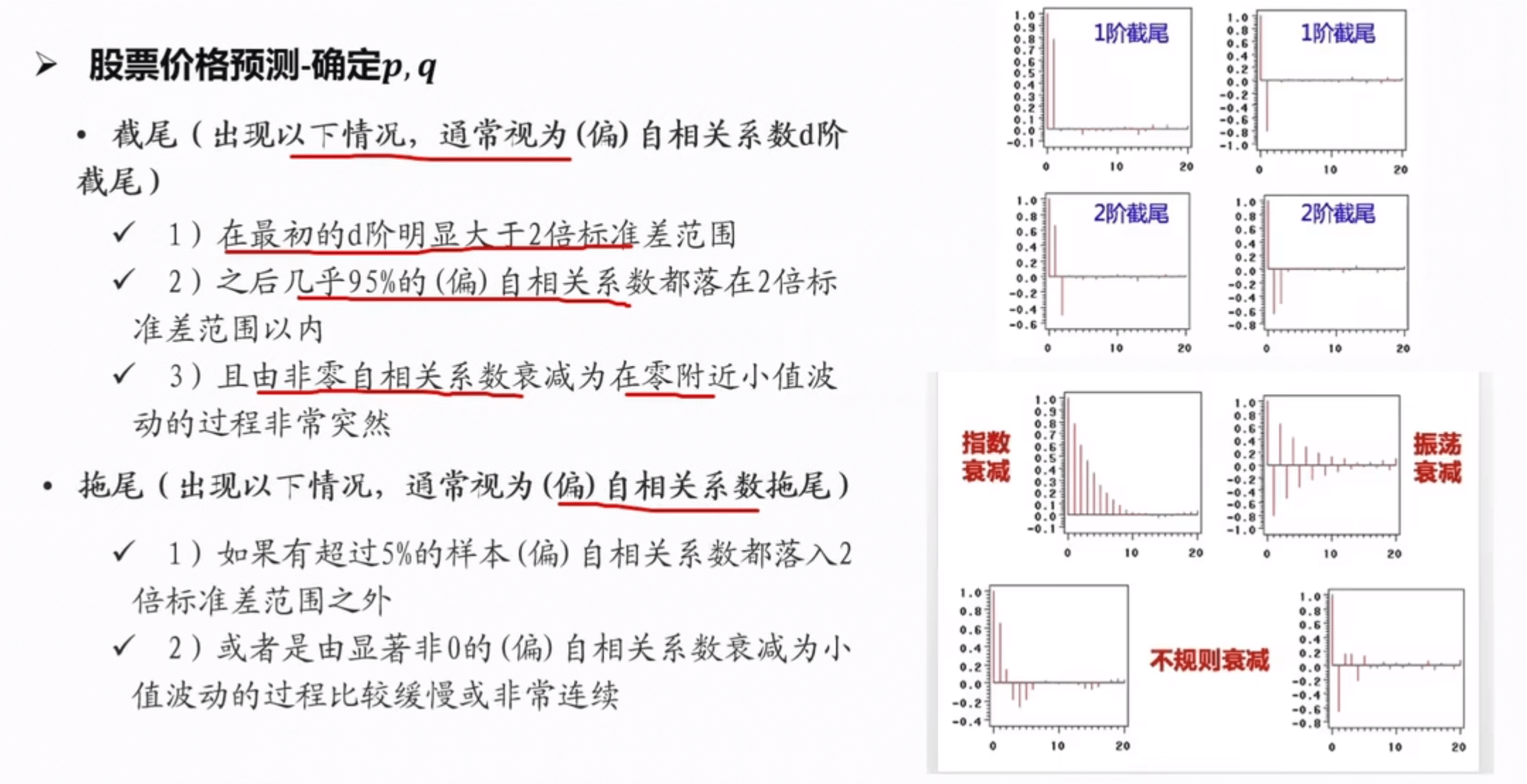
==确定 p,q 值==
d 的值为差分的次数
法一:

法二:BIC 和 AIC 准则
1 | # BIC准则 |
==模型检验==
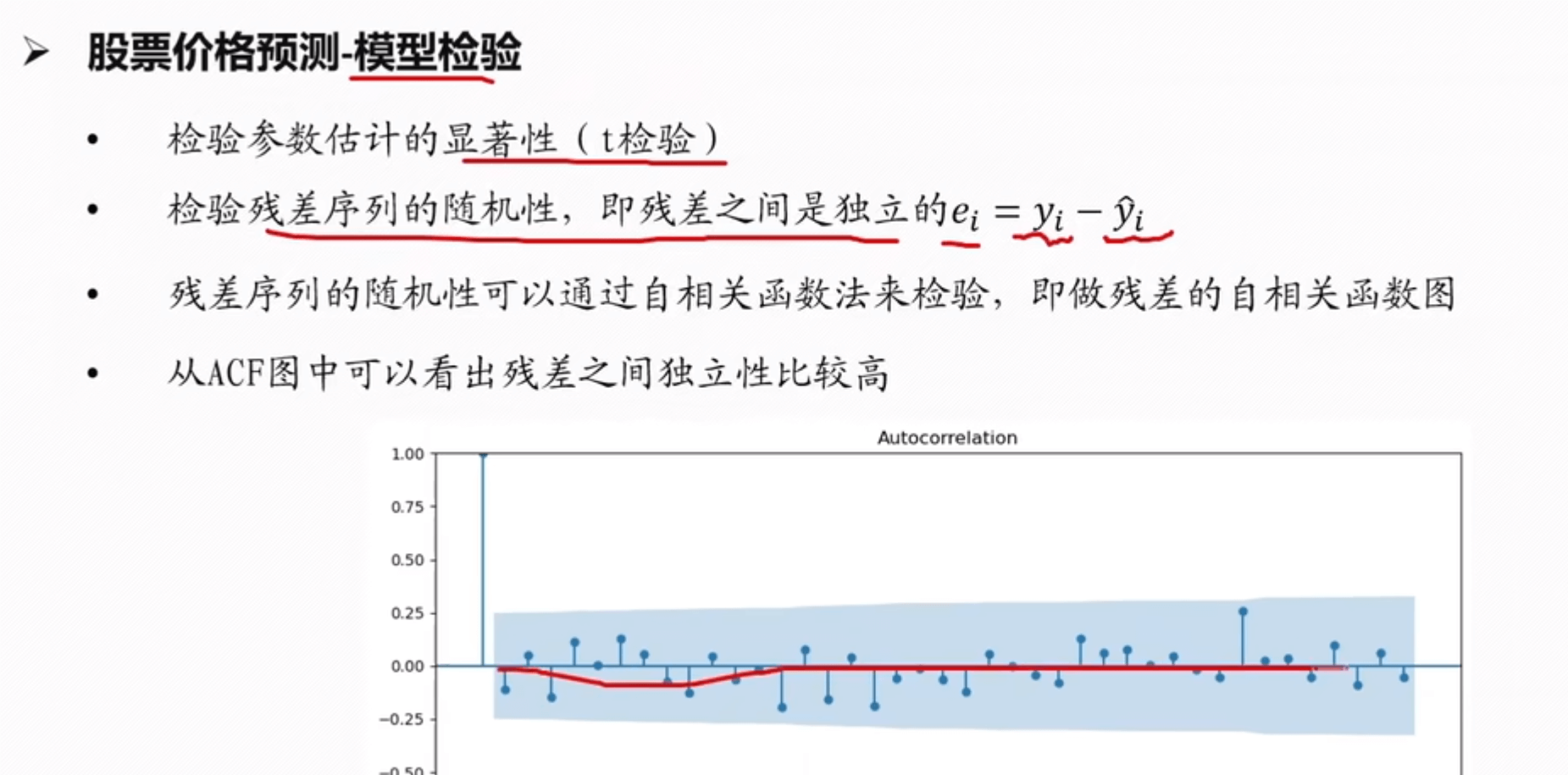
示例部分
代码 copy: 【Python数学建模常用算法代码(一)之ARIMA时间序列预测模型】_arimapython代码-CSDN博客
1 | import pandas as pd |
说明:是在 https://www.bilibili.com/video/BV1EK41187QF 学习后的总结,方便记录,截屏许多公式









